4 Oplossing strategie
4.1 Architectuurpatronen en -principes
De belangrijkste ontwerpprincipes van PLUGIN zijn gebaseerd op de volgende architectuurpatronen1 uit software engineering.
Ten eerste gaan we uit van het pipes & filters patroon, wat een structuur biedt voor systemen die gegevensstromen verwerken. Elke verwerkingsstap voert een bepaalde functie uit en past eventueel een filter (selectie) toe. Gegevens worden tussen aangrenzende stappen doorgegeven. Door filters op nieuw de combineren kunnen afzonderlijke verwerkingsstappen hergebruikt worden voor vergelijkbare ‘data pijplijnen’.
Het pipes & filters patroon is binnen het werkveld van data engineering breed geaccepteerd en kent inmiddels verschillende verschijningsvormen. Binnen eerste generatie data warehouses wordt gesproken van ETL pijplijnen (Extract-Transform-Load), in de nieuwere lakehouse architectuur is de volgorde net ander: ELT pijplijnen (Extract-Load-Transform). In meer algemene zin is het pipes & filters patroon een directed acyclic graph (DAG), zijnde een proces met een start en een eind, zonder feedbackloops met duidelijk gedefineerde functies (stappen). Voor meer details, zie Harby en Zulkernine (2025), Schneider e.a. (2024), Hai e.a. (2023), AbouZaid e.a. (2025), Mazumdar e.a. (2023).
In tweede instantie gebruiken we het layers pattern: het PLUGIN systeem als geheel wordt opgedeeld in deelsystemen in de vijf lagen zoals beschreven in Paragraaf 2.2.2. Hierin maken we op het hoogste niveau onderscheid tussen de processing hub en het datastation. Vervolgens wordt elk van deze deelsystemen opgebouwd met componenten van de composable data stack zoals hieronder is beschreven.
Tot slot gaan we uit van het hub-and-spoke event broker topology patroon, wat de basis geeft hoe decentrale berekeningen bij de datastation worden gecoordineerd en gecombineerd in een federatief netwerk. Wat in PLUGIN de processing hub heet is precies dat (de hub), en de datastations zijn de spaken. Overigens wordt het pipes & filters patroon dus op twee niveaus toegepast: lokale pijplijnen in het datastation, en federatieve pijlijnen die vanuit de hub worden gecoordineerd.
In onderstaande gaan we in meer detail in op een aantal van deze patronen.
4.2 Processing hubs in decentrale netwerken
Om het concept van data visiting toe te passen is een netwerk van datastations nodig die met elkaar verbonden zijn. De manier waarop deze datastations zijn verbonden (de zogenaamde netwerk topologie) is bepalend voor de architectuur van PLUGIN. We kennen grofweg drie netwerk topologieën: centraal, decentraal en gedistribueerd.2
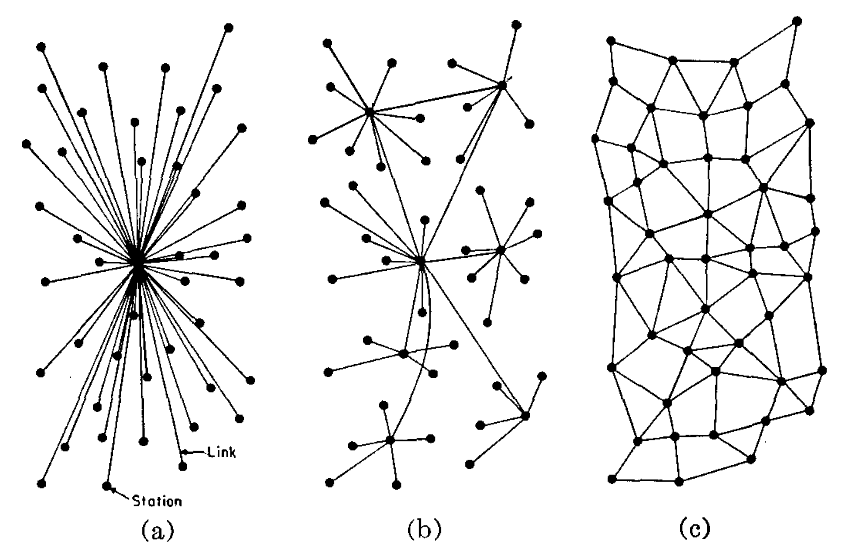
Voor het uitvoeren van gefedereerde berekeningen zijn er twee mogelijkheden:3
- Datastations zijn verbonden met één centrale coordinator (ook wel bekend als een hub-and-spoke netwerk).
- Datastations zijn met elkaar verbonden door middel van een een distribueerd netwerk (ook wel peer-to-peer genoemd).
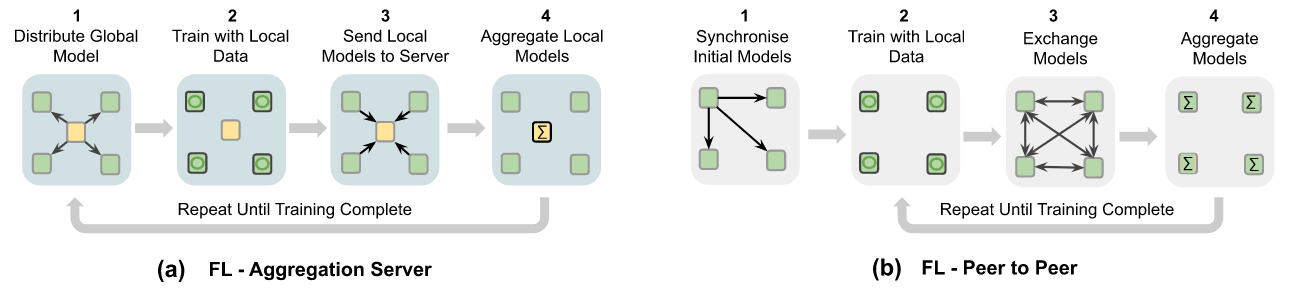
De meest gebruikte vorm van gefedereerde gegevensverwerking gaat uit van een centrale coordinator die de datastations aanstuurt. Het concept van een Federated Database System (FDBS) is in 1985 beschreven en wordt al jaren gebruikt voor het uitvoeren van gefedereerde analyse (queries) over meerdere databases.4 Het concept van gefedereerd leren zoals in 2017 door Google is geintroduceerd5 maakt ook gebruik van een centrale coordinator functie.
In de beschrijving van datastations gaan we dus uit van een processing hub als een centrale coordinator, waarop de datagebruiker inlogt om toegang om berekeningen te kunnen initieren in het netwerk van datastations. Federated computing met een peer-to-peer netwerk zijn expliciet niet in scope van de PLUGIN architectuur.
Daarnaast moet het in de context van de EHDS mogelijk zijn om te werken met federations of federations. De hybride architectuur van PLUGIN die we voor ogen hebben kent een gelaagdheid van knooppunten. Denk bijvoorbeeld aan een zorginstelling die participeert in een regionaal samenwerkingsverband, waarbij vervolgens verschillende regionale knooppunten opgaan in een landelijk netwerk. Daarbovenop kunnen landelijke knooppunten onderdeel uitmaken van een Europese federatie. In de uitwerking van de architectuur gaan we daarom uit van een decentraal netwerk dat een gelaagdheid kent van meerdere netwerken, elk met een centrale coordinator (netwerk type b in bovenstaande illustratie).
4.3 Composable datastations
De datastations zijn ontworpen met de principes van de composable data stack6:
- Modulariteit: Componenten (bouwstenen) kunnen onafhankelijk van elkaar worden vervangen of geschaald.
- Interoperabiliteit: Dankzij open standaarden kunnen verschillende systemen zonder kostbare conversies samenwerken.
- Ontkoppeling: De fysieke opslag (storage), de data verwerking (compute) en de schema-informatie (catalog) zijn strikt van elkaar gescheiden.
In traditionele systemen is data vaak opgeslagen in een eigen, gesloten formaat dat alleen door de bijbehorende database-engine gelezen kan worden. In de Composable Data Stack wordt de opslaglaag geagnostiseerd.
- Open bestandsformaten: Data wordt opgeslagen in gestandaardiseerde kolomgeoriënteerde formaten zoals Apache Parquet. Dit maakt de data toegankelijk voor een breed scala aan tools zonder dat de data verplaatst of getransformeerd hoeft te worden.
- Lakehouses: Door gebruik te maken van object storage (zoals S3 of Azure Blob) als centrale bron, fungeert de opslaglaag als een ‘single source of truth’ die onafhankelijk van de rekenkracht kan groeien.
Door de ontkoppeling van opslag wordt de ‘compute-laag’ vervangbaar. Dit stelt organisaties in staat om verschillende gespecialiseerde engines te gebruiken op dezelfde dataset.
- Engine-Agnostische Verwerking: Een organisatie kan SQL-queries uitvoeren met de ene engine (bijv. DuckDB of Trino), terwijl een data scientist tegelijkertijd machine learning-modellen traint met een andere tool (bijv. PyTorch), direct op dezelfde data.
- Efficiënte data-uitwisseling: Om de snelheid tussen verschillende compute-engines te waarborgen, fungeert Apache Arrow als de lingua franca voor data in het geheugen. Dit minimaliseert de overhead van serialisatie en deserialisatie (het omzetten van dataformaten).
De verbindende factor in een gedecentraliseerde stack is de metadatalaag. Zonder centrale metadata ontstaat er versnippering.
- Tabelformaten: Technologieën zoals Apache Iceberg of Delta Lake voegen een abstractielaag toe bovenop de ruwe bestanden. Ze beheren metadata over welke bestanden bij welke tabel horen, ondersteunen transacties (ACID) en maken tijdreizen (time-travel) door data mogelijk.
- Catalogus: De catalogus fungeert als de inventaris van de gehele stack. Het houdt bij waar de data staat, wie de eigenaar is en wat de structuur (schema) is. Dit is essentieel voor de vindbaarheid en governance, vergelijkbaar met de FAIR-principes (Findable, Accessible, Interoperable, Reusable).
De catalogus in de composable data stack refereert naar het information schema van de data. Hiervoor zullen open standaarden zoals Apache Iceberg en DuckLake worden gebruikt. Deze catalogus is anders dan de metadata catalogus die op DCAT is gebaseerd en als generieke functie is beschreven binnen het landelijk dekkend netwerk.
Parallel aan de decompositie van dataverwerkingssystemen is de capaciteit van single-node processing units zodanig toegenomen dat het inmiddels mogelijk is om tot circa 10 TB aan data op een enkele machine te verwerken en analyseren.7 In het ontwerp van een datastation gaan we er dus vanuit dat het systeem als geheel op een (virtuele) machine past, wat de complexiteit van een datastation aanzienlijk vereenvoudigd.